Update: I will give an online talk on my work with Alex in Voiculescu’s Probabilistic Operator Algebra Seminar on Monday, Feb 3, at 9am Pacific time (which is 6pm German time). In order to get the online link for the talk you should write to jgarzav at caltech dot edu.
In the post “Structured random matrices and cyclic cumulants: A free probability approach” by Bernard and Hruza I mentioned the problem about the effect of non-linear functions on random matrices and showed some plots from my ongoing joint work with Alexander Wendel. Finally, a few days ago, we uploaded the preprint to the arXiv.
What is this about? Consider a random matrix ensemble XN which has a limiting eigenvalue distribution for N going to infinity. In the machine learning context applying non-linear functions to the entries of such matrices plays a prominent role and the question arises: what is the asymptotic effect of this operation. There are a couple of results in this direction; see, in particular, the paper by Pennington and Worah and the one of Peche. However, it seems that they deal with quite special choices for XN, like a product of two independent Wishart matrices. In those cases the asymptotic effect of applying the non-linearity is the same as taking a linear combination of the XN with an independent Gaussian matrix. The coefficients in this linear combination depend only on a few quantities calculated from the non-linear function. Such statements are often known as Gaussian equivalence principle.
Our main contribution is that this kind of result is also true much more generally, namely for the class of rotationally invariant matrices. The rotational invariance is kind of the underlying reason for the specific form of the result. Roughly, the effect of the non-linearity is a small deformation of the rotational invariance, so that the resulting random matrix ensemble still exhibits the main features of rotational invariance. This provides precise enough information to control the limiting eigenvalue distribution.
We consider the real symmetric case, that is, symmetric orthogonally invariant random matrices. Similar results hold for selfadjoint unitarily invariant random matrices, or also for corresponding random matrices without selfadjointness conditions.
In addition to what I already showed in the above mentioned previous post, we extended the results now also to a multi-variate setting. This means we can also take, again entrywise, a non-linear function of several jointly orthogonally invariant random matrices. The asymptotic eigenvalue distribution after applying such a function is the same as for a linear combination of the involved random matrices and an additional independent GOE. As an example, take the two random matrices XN=AN2– BN and YN=AN4+CNAN+ANCN, where AN, BN, CN are independent GOEs. Note that, by the appearance of AN in both of them, they are not independent, but have a correlation. Nevertheless, they are jointly orthogonally invariant — that is, the joint distribution of all their entries does not change if we conjugate both of them by the same orthogonal matrix. We consider now the non-linear random matrix max(XN,YN), where we take entrywise the maximum of the corresponding entries in XN and YN. Our results say that asymptotically this should have the same eigenvalue distribution as the linear model aXN+ bYN + cZN, where ZN is an additional GOE, which is independent from AN, BN, CN, and where a, b, c are explicitly known numbers. The next plot superimposes the two eigenvalue distributions.
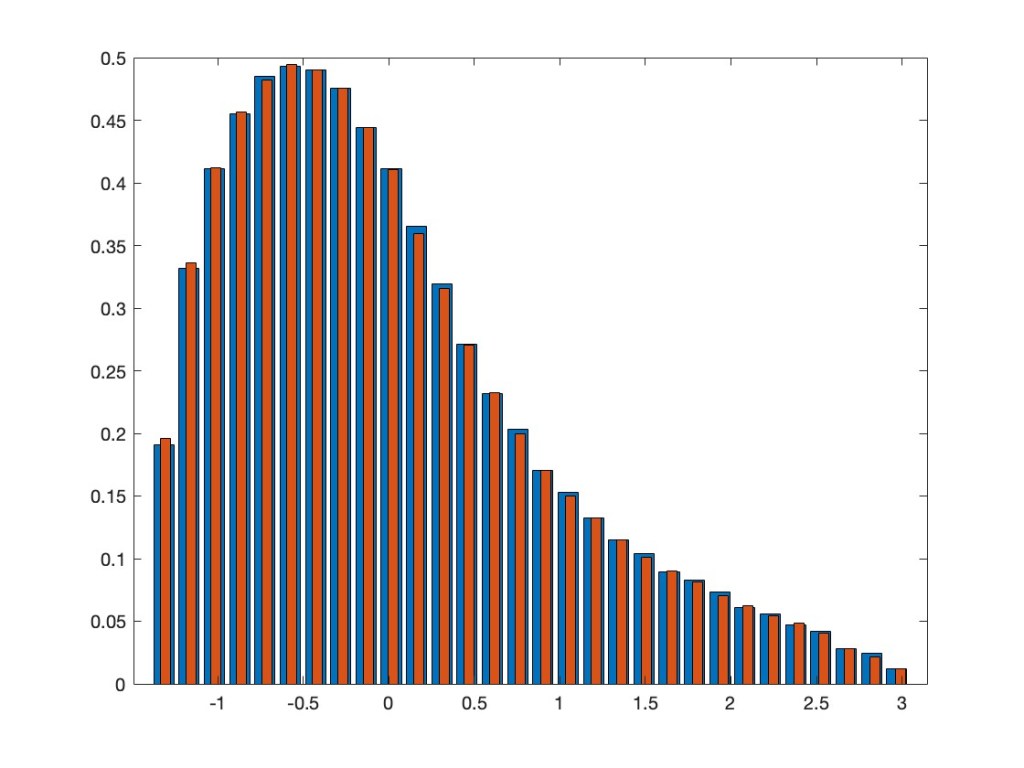
If you want to know more, in particular, why this is true and how the coefficients in the linear model are determined in terms of the non-linear function, see our preprint Entrywise application of non-linear functions on orthogonally invariant random matrices.

 and can derive from this that no two eigenvalues of absolute value smaller than 0.1 are possible, because otherwise we would have the following estimate
and can derive from this that no two eigenvalues of absolute value smaller than 0.1 are possible, because otherwise we would have the following estimate 
 .
. , where the
, where the  are free semicircular elements and the
are free semicircular elements and the 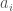 are ordinary mxm matrices, with the only restriction that their entries are integers. We assume that such an S is invertible (as an unbounded operator) ; one can show that then its Fuglede-Kadison determinant
are ordinary mxm matrices, with the only restriction that their entries are integers. We assume that such an S is invertible (as an unbounded operator) ; one can show that then its Fuglede-Kadison determinant  is not equal to zero. The main question is whether we have a uniform lower estimate for
is not equal to zero. The main question is whether we have a uniform lower estimate for  .
. the corresponding completely positive map
the corresponding completely positive map
 and let
and let 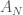 denote the Gaussian block random matrix
denote the Gaussian block random matrix

 is defined as the infimum of
is defined as the infimum of  over all
over all  for which det(b)=1.
for which det(b)=1.