
The evolution of some papers of Bernard and Hruza in the context of “Quantum Symmetric Simple Exclusion Process” (QSSEP) have been addressed before in some posts, here and here. Now there is a new version of the latest preprint, with the more precise title “Structured random matrices and cyclic cumulants : A free probability approach“. I think the connection of the considered class of random matrices with our free probability tools (in particular, the operator-valued ones) is getting nicer and nicer. One of the new additions in this version is the proof that applying non-linear functions entrywise to the matrices (as is usually done in the machine learning context) does not lead out of this class and one can actually describe the effect of such an application.
I consider all this as a very interesting new development which connects to many things, and I will try to describe this a bit more concretely in the following.
For the usual unitarily invariant matrix ensembles we know that the main information about the entries which contributes in the limit to the calculation of the matrix distribution are the cyclic classical cumulants (or ”loop expectation values”). Those are cumulants of the entries with cyclic index structure 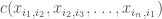


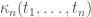

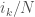
As I mentioned at the beginning I am also intrigued by the effect of applying non-linear functions to the entries of our matrices. This is something, we usually don’t do in ”classical” random matrix theory, but which has become quite popular in recent years in the machine learning context. There are statements which go under the name of Gaussian equivalence principle, which say that the effect of the non-linearity is in many cases the same as adding an independent Gaussian random noise. Actually, this is usually done for special random matrices, like products of Wishart matrices. However, this seems to be true more general; I was convinced that this is valid for unitarily invariant matrices, but the paper of Bernard and Hruza shows that even in their more general setting one has results of this type.
In order to give a concrete feeling of what I am talking about here, let me give a concrete numerical example for the unitarily invariant case. Actually, I prefer her the real setting, i.e., orthogonal invariant matrices. For me canonical examples of those are given by polynomials in independent GOE, so let us consider here 
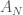
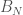
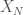
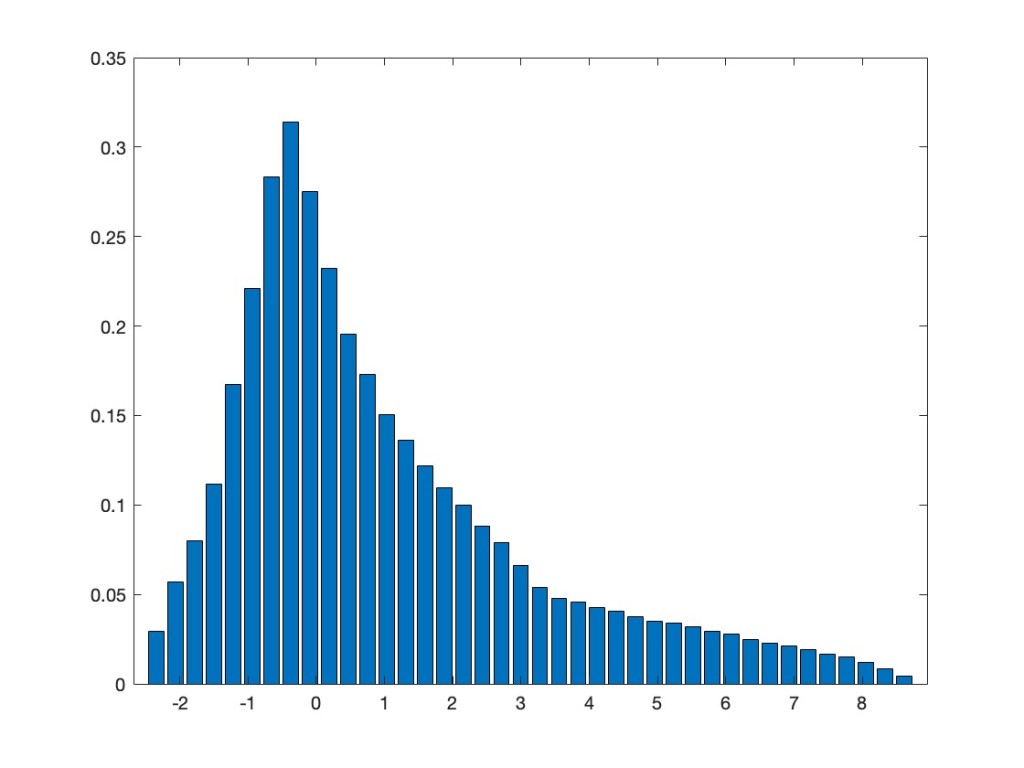
We apply now a non-linear function to the entries of 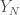

For the function f, let’s take the machine learning favorite, namely the ReLU function, i.e., 
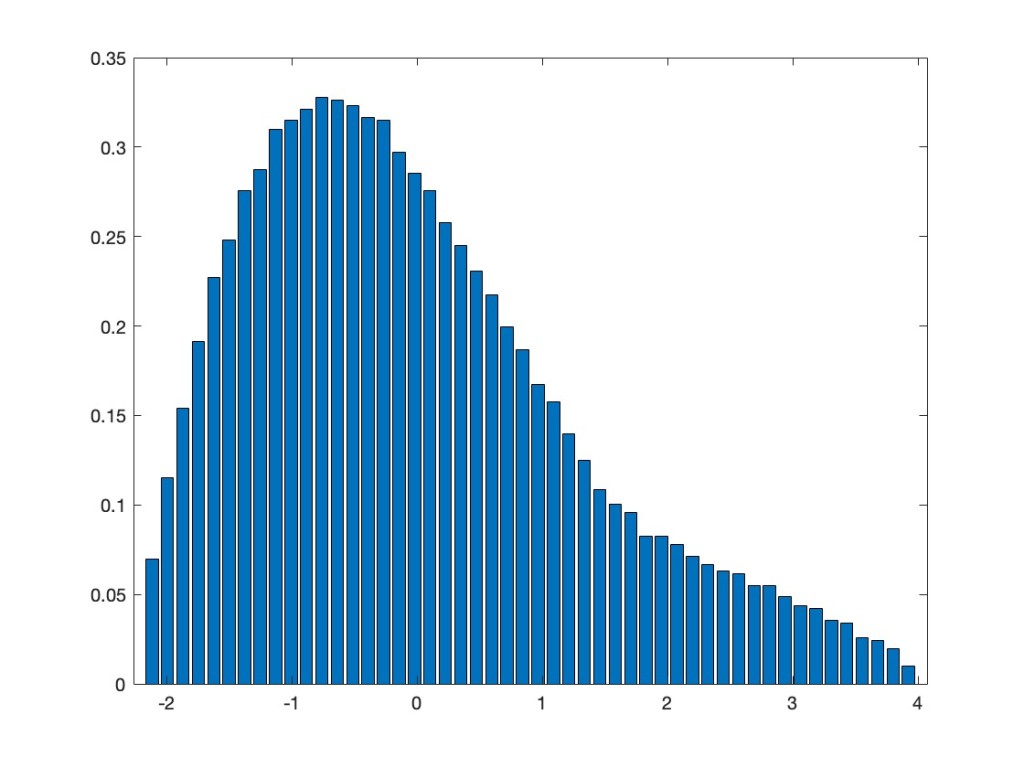
But now the Gaussian equivalence principle says that this 
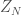
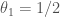
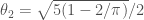
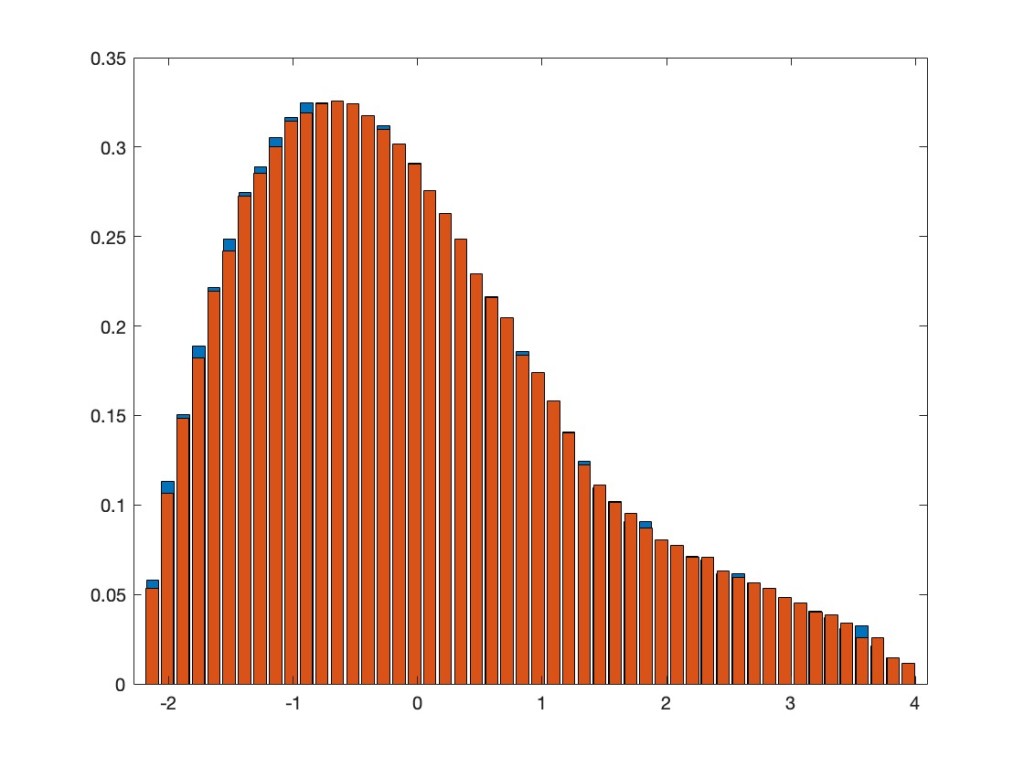
One should note that the ReLU functions does not fall into the class of (polynomial or analytic) functions, for which the results are usually proved, but ReLU is explicit enough, so that probably one could also do this more directly in this case. Anyhow, all this should just be an appetizer, there is still quite a bit to formulate and prove in this direction, but I am looking forward to a formidable feast in the end.

nices!! The noncommutative Edmonds’ problem revised: how to calculate the inner rank of matrices in noncommuting variables
LikeLike
Pingback: Understanding Non-Linearity in Random Matrices | Free Probability Theory