
It’s now almost a year that we have been told that Connes’ embedding conjecture is not a conjecture anymore, but that it’s actually false. In principle, this is great news as it should open totally new playgrounds, with von Neumann algebras never seen before. The only problem is that we still have not seen them. I am sure that many are looking for them but as far as I am aware nobody outside the quantum information community was able to shed more light on the refutation of Connes’ embedding.
As a believer in the power of non-commutative distributions I tried all my arsenal of moments, cumulants, or Cauchy transforms to get a grasp on how such a non-embeddable von Neumann algebra could look like — of course, without any success. But let me say a few more words an some of my thoughts – if only to come up with a bit longer post for the end of the year.
In our non-commutative distribution language, the refutal of Connes’ embedding says that there are operators in a tracial von Neumann algebra whose mixed moments cannot be approximated by moments of matrices with respect to the trace. We have quite a few of distributions in free probability theory, but the main problem in the present context is that all of them usually can be approximated by matrices, and also all available constructions (like taking free products) preserve such approximations (in particular, since we can model free independence via conjugation by unitary random matrices). Very roughly: our constructions of distributions take some input and then produce some distribution — however, if the input is embeddable, then the output will be so, too. Thus I cannot use those constructions directly to make the leap from our known universe to the new ones which should be out there. The only way I see to overcome this obstruction is to look for distributions which create themselves “out of nothing” via such constructions, i.e., for fixed point distributions of those constructions. For such fixed point distributions I see at least no apriori reason to be embeddable.
But is there any way to make this concrete? My naive attempt is to use the transition from moments to cumulants (or, more analyticially, from Cauchy transforms to R-transforms) for this. We know that infinitely divisible distributions (in particular, compound Poisson ones) are given in the form that their free cumulants are essentially the moments of some other distribution. So I am trying to find reasonable fixed points of this mapping, i.e., I am looking for distributions whose cumulants are (up to scaling or shift) the same as their moments. Unfortunately, all concrete such distributions seem to arise via solving the fixed point equation in an iterative way – which is also bad from our embedding point of view, since those iterations also seem to preserve embeddability. So I have to admit complete and utter failure.
Anyhow, if the big dreams are not coming true, one should scale down a bit and see whether anything interesting is left … so let me finally come to something concrete, which might, or might not, have some relevance …
In the case of one variable we are looking on probability measures, and as those can be approximated by discrete measures with uniform weights on the atoms (thus by the distribution of matrices), this situation is not relevant for Connes’ embedding question. However, I wonder whether a fixed point of the moments-to-cumulants mapping in this simple situation has any relevance. The only meaningful mapping in this case seems to be that I take a moment sequence, shift it by 2 and then declare it as a cumulant sequence — necessarily of an infinitely divisible distribution. Working out the fixed point of this mapping gives the following sequence of even moment/cumulants: 1, 1, 3, 14, 84, 596. The Online Encyclopedia of Integer Sequences labels this as A088717 — which gives, though, not much more information than the fixed point equation for the generating power series.
The above moment-cumulant mapping was of course using free cumulants. Doing the same with classical cumulants gives by a not too careful quick calculation the sequence 1, 1, 4, 34, 496, which seems to be https://oeis.org/A002105 — which goes under the name ”reduced tangent numbers”. There are also a couple of links to various papers, which I still have to check …
Okay, I suppose that’s it for now. Any comment on the relevance or meaning of the above numbers, or their probability distributions, would be very welcome – as well, as any news on Connes’ conjecture.
 that
that 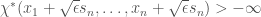 , if
, if  are free semicircular variables which are free from
are free semicircular variables which are free from  . The same property for the microstates free entropy
. The same property for the microstates free entropy  , however, would imply that
, however, would imply that 