

Update: The paper has now been published in Foundations of Computational Mathematics as an open access article. Here is a link.
My paper with Johannes and Tobias on the noncommutative Edmonds’ problem has got a total makeover; the new revised version appeared just on the arXiv. It relies now heavily on the recent results of Tobias and mine on the Fuglede-Kadison determinant of matrix-valued semicircular elements. But also, the organization of the paper is now much more reader-friendly – at least we hope so. Everything you need to know can be gotten from the first three sections; if you need proofs, read the rest.
Let me first recall the noncommutative Edmonds’ problem. Consider a matrix

where the 
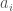
The noncommutative Edmonds’ problem asks whether A is invertible over the noncommutative rational functions in the

In terms of 
This noncommutative Edmonds’ problem has become quite prominent in recent years and there are now a couple of deterministic algorithms; see, in particular, the work of Garg, Gurvits, Oliveira and Widgerson.
Let me now recall our noncommutative probabilistic approach to the noncommutative Edmonds’ problem, by replacing the formal variables by concrete operators on infinite-dimensional Hilbert spaces. And a particular nice, and our favorite, choice for the analytic operators are freely independent semicircular variables 

is a matrix-valued semicircular element.
Since one can reduce the general case to the selfadjoint one, it suffices to consider in the following the selfadjoint situation. Then the corresponding S is also a selfadjoint operator, hence its distribution is a probability measure on the real line. By our work of the last ten years or so we know that the invertibility of the formal matrix A over the noncommutative rational functions is equivalent to the invertibility of S as an unbounded operator. But this is equivalent to the question whether S has a trivial kernel, which is equivalent to the question whether its distribution has no atom at zero.
And we know how to calculate the distribution 

on the complex upper half plane is of the form

where G(z) is given as the unique solution of the matrix-valued equation

in the lower half-plane of the NxN-matrices. One should note that for each z in the upper complex half plane there is (by some old results of mine with Reza Rashidi Far and Bill Helton) exactly one solution G(z) in the complex lower half-plane of the matrices. And, finally, we know that

So it seems, problem solved: Calculate the Cauchy transform and use the Stieltjes inversion formula to get the mass of the distribution at zero. We can even make this very concrete; what we need to consider is

in the limit where the positive real number y tends to zero. This limit is the mass of the atom at zero.
This is nice, but of course we cannot calculate anything analytically here, but have to rely on numerical approximations. So the question is, for which y should we calculate 
Consider, for example, the matrix-valued semicircular element

If you want to know how we can get out of our machinery that the atom at zero of its distribution has mass 0.5 (that is, its noncommutative rank is 2), have a look at the revised version of our paper!
